Mirabelle, a powerful stream processing engine
Mirabelle is a stream processing engine which can be used to aggregate events, metrics, logs and traces.
Its powerful and extensible DSL allows you to define computations on a stream of data. Mirabelle offers natively a lot of functions (time windows, mathematical operations, transforming data, relabeling, etc.) which can be easily combined according to your needs.
It can be used for a lot of use cases like monitoring, fraud detection, alerting, to route events and metrics between different systems…
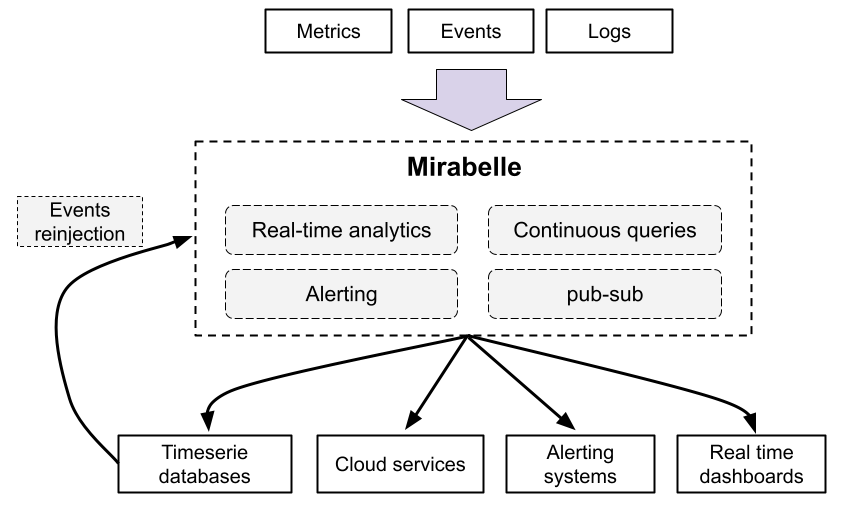
Mirabelle can also route events to external systems (timeseries databases, logging systems, cloud monitoring services, etc.), fire alerts (e.g. to Pagerduty), write data into files and more.
It also implements a publish-subscribe system, which allows you to see in real time (through Websockets) events flowing into streams.
Mirabelle is currently in alpha, but I’m eager to receive feedback.
Mirabelle supports multiple inputs protocols (including the Riemann one)
Mirabelle is heavily inspired by Riemann. Actually, parts of the Mirabelle codebase (like the TCP server implementation for example) were taken from Riemann (these parts are mentioned in the codebase).
I would like to thank all Riemann maintainers and contributors for this amazing tool.
Mirabelle supports the same protocol than Riemann. It means all Riemann tooling and integrations should work seamlessly with Mirabelle (which also contains a lot of new features).
Mirabelle also provides an HTTP API and natively supports receiving metrics in Prometheus remote write format. See the API documentation for more information about Prometheus integration.
It also supports Opentelemetry traces as input.
Streams clocks, real time, continuous queries
In Mirabelle (and unlike Riemann), all streams advance based on the time of the events they receive. Because of that, it’s super easy to reason about your streams, and to unit test them (the same inputs always produce the same outputs).
In Mirabelle, events arrive by default in streams defined in the Mirabelle configuration file. As said previously, the Mirabelle clock for a stream will only advance if you send new events.
You can also in Mirabelle instantiate steams on the fly (using the Mirabelle HTTP API) and push events into these new streams. All streams have their own clocks and can advance independently. You can choose on which stream clients should push events, and define which streams should be used by default.
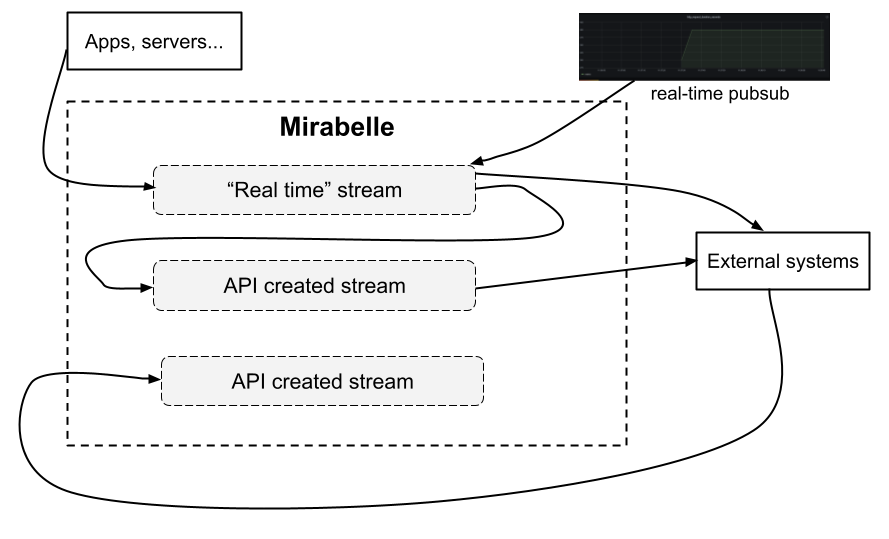
You can have real time streams receiving events directly from your servers and applications, and some streams working on old (and maybe ordered) data coming from various databases. Like that, you can have the best of both words: real time analytics, and run analytics on old data using continuous queries for example.
Being able to use the same tool for stream processing and to work on historical data is interesting. You could for example have a Mirabelle instance used for real time stream processing, and another one (or even the same one on dedicated streams) working on old data… It’s up to you to decide !
Stream example, with unit tests
Let’s say a web application is pushing the duration (in seconds) of the HTTP requests it receives. This metric could be modeled using this Mirabelle event
{:host "my-server"
:service "http_request_duration_seconds"
:application "my-web-app"
:time 1619731016,145
:tags ["web"]
:metric 0.5}
You could write a Mirabelle stream which will compute on the fly the quantiles for this metric. In this example, Mirabelle will split the received events into 60 seconds windows, then compute the percentiles, set the event :state to “critical” and send an alert to Pagerduty if the 0.99 quantiles is greater than 1 second.
(streams
(stream {:name :percentiles :default true}
(where [:= :service "http_request_duration_seconds"]
(fixed-time-window {:duration 60}
(coll-percentiles [0.5 0.75 0.99]
(where [:and [:= :quantile "0.99"]
[:> :metric 1]]
(with :state "critical"
(tap :alert)
(output! :pagerduty))))))))
The tap action is an action which will be only enabled in test mode, and which will save in a tap named :alert events passing by it. Indeed, everything can be unit tested easily in Mirabelle.
A test for this stream would be:
{:percentiles {:input [{:service "http_request_duration_seconds"
:metric 0.1
:time 1}
{:service "http_request_duration_seconds"
:metric 1.2
:time 30}
{:service "http_request_duration_seconds"
:metric 0.2
:time 70}]
:tap-results {:alert [{:service "http_request_duration_seconds"
:metric 1.2
:time 30
:quantile "0.99"
:state "critical"}]}}}
In this test, we inject into the :percentiles stream three events, and we verify that the tap named :alert contains the expected alert (the 0.99 quantile is greater than 1) generated for these events.
Thanks to Clojure datastructures, there is no side effects between streams and actions. It’s OK to modify events in parallel (in multiple threads) and to have multiple branches per stream. You can even pass events between streams (like described here). You are free to organize streams and how they communicate between each other exactly how you want to; the tool and its DSL will not limit you.
Here is a more complete and commented example, with multiple actions performed in one stream:
(streams
(stream {:name :multiple-branches}
(where [:= :service "http_request_duration_seconds"]
(with :ttl 60
;; push everything into influxdb
(output! :influxdb)
;; index events in memory by host and service
(index [:host :service])
;; by will generate a branch for each :host value. Like that, downstream
;; computations will be per host and will not conflict between each other
(by {:fields [:host]}
;; if the metric is greater than 1 for more than 60 seconds
;; Pass events downstream
(above-dt {:duration 60 :threshold 1}
;; pass the state to critical
(with :state "critical"
;; one alert only every 60 sec to avoid flooding pagerduty
(throttle {:duration 60 :count 1}
(output! :pagerduty)))))))))